动态规划(dynamic programming) 是一个重要的算法范式,它将一个问题分解为一系列更小的子问题,并通过存储子问题的解来避免重复计算,从而大幅提升时间效率。
在本节中,我们从一个经典例题入手,先给出它的暴力回溯解法,观察其中包含的重叠子问题,再逐步导出更高效的动态规划解法。
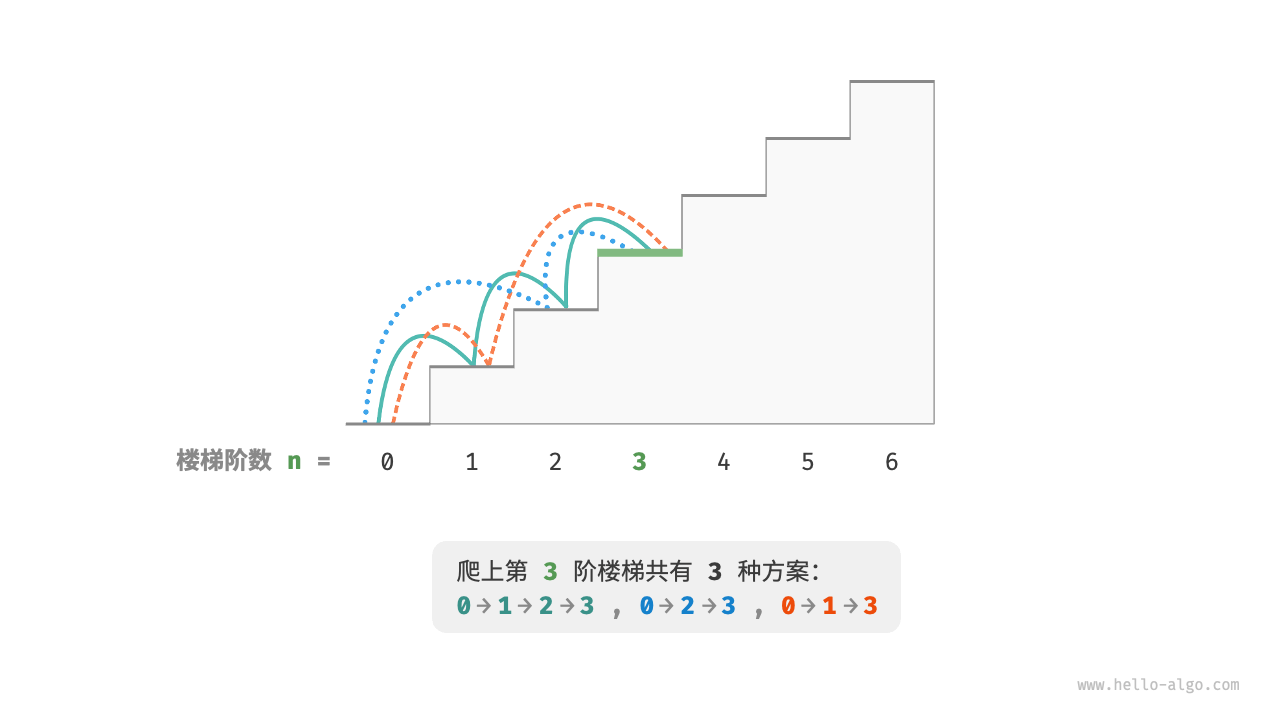
给定一个共有 n n n 1 1 1 2 2 2
如下图所示,对于一个 3 3 3 3 3 3
本题的目标是求解方案数量,我们可以考虑通过回溯来穷举所有可能性 。具体来说,将爬楼梯想象为一个多轮选择的过程:从地面出发,每轮选择上 1 1 1 2 2 2 1 1 1
void backtrack (vector<int > &choices, int state, int n, vector<int > &res) if (state == n) res[0 ]++; for (auto &choice : choices) { if (state + choice > n) continue ; backtrack (choices, state + choice, n, res); } } int climbingStairsBacktrack (int n) vector<int > choices = {1 , 2 }; int state = 0 ; vector<int > res = {0 }; backtrack (choices, state, n, res); return res[0 ]; }
回溯算法通常并不显式地对问题进行拆解,而是将求解问题看作一系列决策步骤,通过试探和剪枝,搜索所有可能的解。
我们可以尝试从问题分解的角度分析这道题。设爬到第 i i i d p [ i ] dp[i] d p [ i ] d p [ i ] dp[i] d p [ i ]
d p [ i − 1 ] , d p [ i − 2 ] , … , d p [ 2 ] , d p [ 1 ] dp[i-1], dp[i-2], \dots, dp[2], dp[1]
d p [ i − 1 ] , d p [ i − 2 ] , … , d p [ 2 ] , d p [ 1 ]
由于每轮只能上 1 1 1 2 2 2 i i i i − 1 i - 1 i − 1 i − 2 i - 2 i − 2 i − 1 i -1 i − 1 i − 2 i - 2 i − 2 i i i
由此便可得出一个重要推论:爬到第 i − 1 i - 1 i − 1 i − 2 i - 2 i − 2 i i i 。公式如下:
d p [ i ] = d p [ i − 1 ] + d p [ i − 2 ] dp[i] = dp[i-1] + dp[i-2]
d p [ i ] = d p [ i − 1 ] + d p [ i − 2 ]
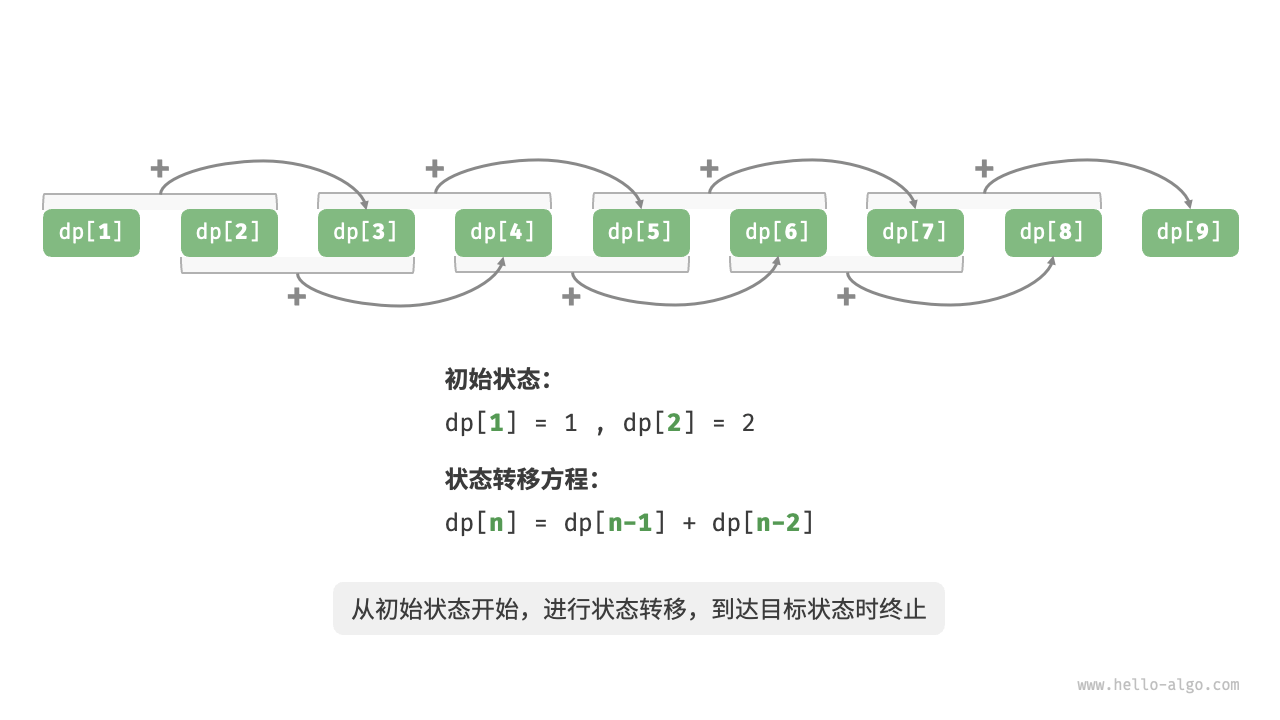
这意味着在爬楼梯问题中,各个子问题之间存在递推关系,原问题的解可以由子问题的解构建得来 。下图展示了该递推关系。
我们可以根据递推公式得到暴力搜索解法。以 d p [ n ] dp[n] d p [ n ] 递归地将一个较大问题拆解为两个较小问题的和 ,直至到达最小子问题 d p [ 1 ] dp[1] d p [ 1 ] d p [ 2 ] dp[2] d p [ 2 ] d p [ 1 ] = 1 dp[1] = 1 d p [ 1 ] = 1 d p [ 2 ] = 2 dp[2] = 2 d p [ 2 ] = 2 1 1 1 2 2 2 1 1 1 2 2 2
观察以下代码,它和标准回溯代码都属于深度优先搜索,但更加简洁:
int dfs (int i) if (i == 1 || i == 2 ) return i; int count = dfs (i - 1 ) + dfs (i - 2 ); return count; } int climbingStairsDFS (int n) return dfs (n); }
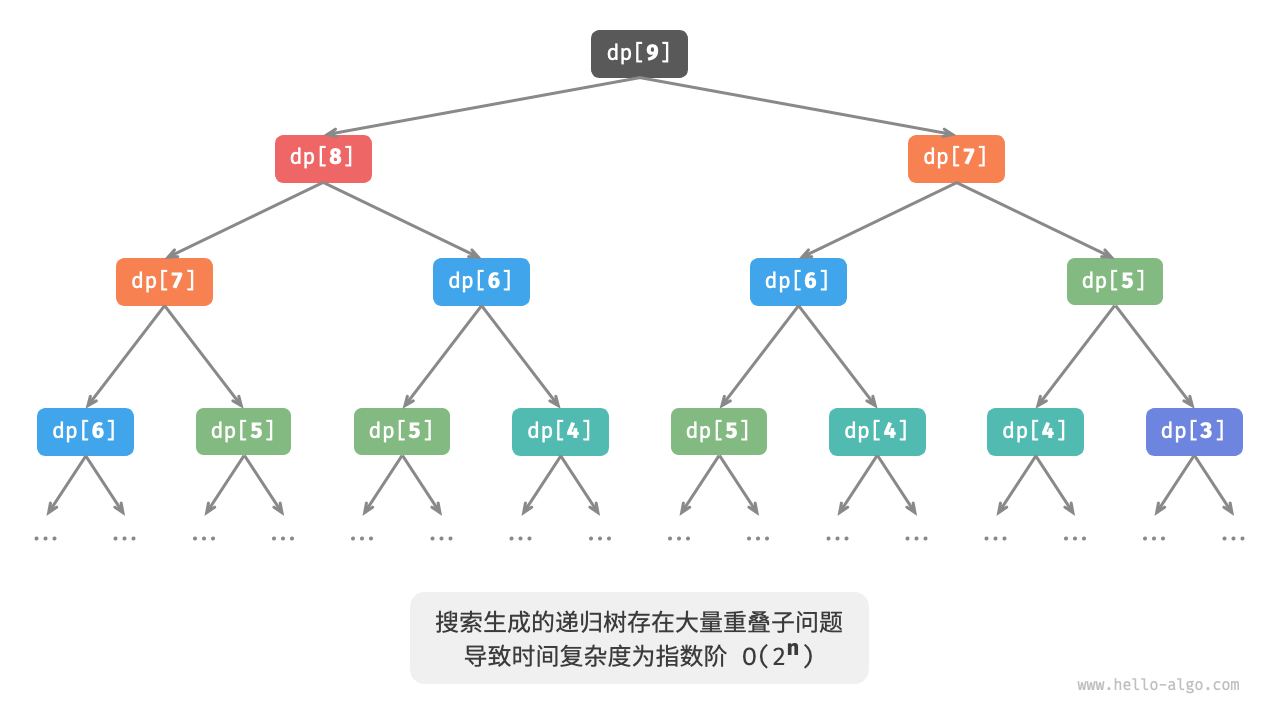
下图展示了暴力搜索形成的递归树。对于问题 d p [ n ] dp[n] d p [ n ] n n n O ( 2 n ) O(2^n) O ( 2 n ) n n n
观察上图,指数阶的时间复杂度是“重叠子问题”导致的 。例如 d p [ 9 ] dp[9] d p [ 9 ] d p [ 8 ] dp[8] d p [ 8 ] d p [ 7 ] dp[7] d p [ 7 ] d p [ 8 ] dp[8] d p [ 8 ] d p [ 7 ] dp[7] d p [ 7 ] d p [ 6 ] dp[6] d p [ 6 ] d p [ 7 ] dp[7] d p [ 7 ]
以此类推,子问题中包含更小的重叠子问题,子子孙孙无穷尽也。绝大部分计算资源都浪费在这些重叠的子问题上。
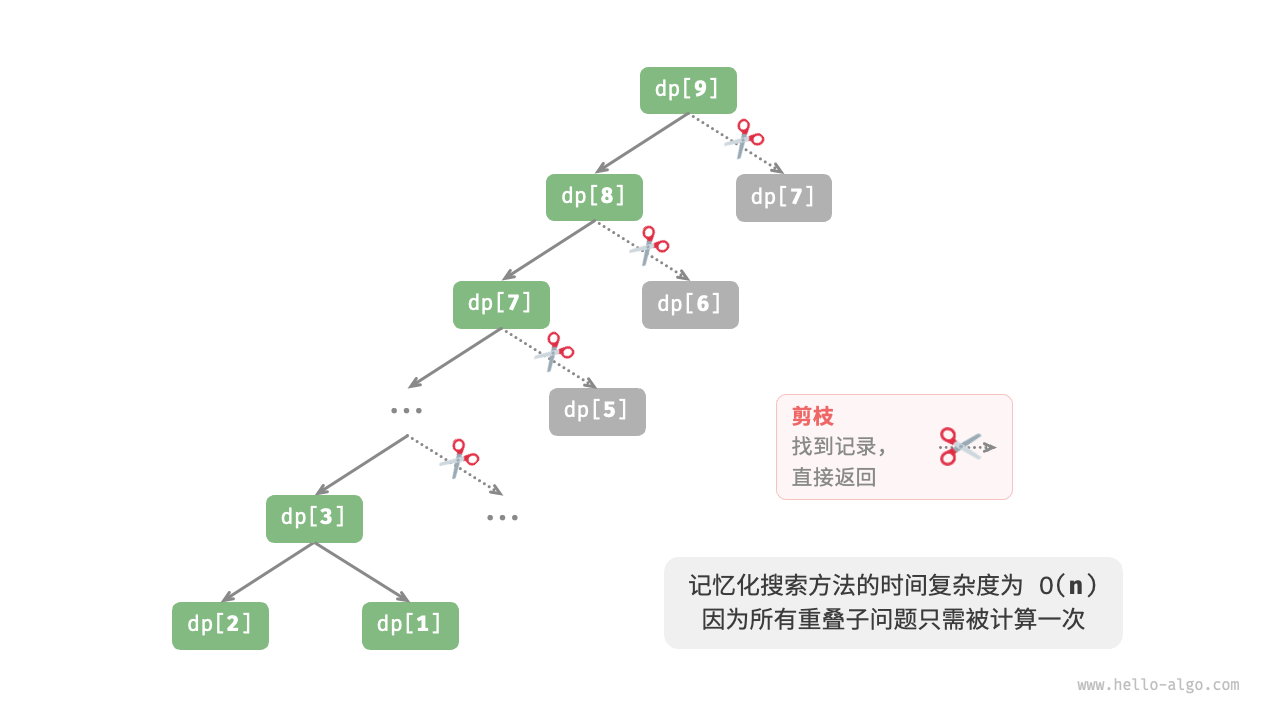
为了提升算法效率,我们希望所有的重叠子问题都只被计算一次 。为此,我们声明一个数组 mem 来记录每个子问题的解,并在搜索过程中将重叠子问题剪枝。
当首次计算 d p [ i ] dp[i] d p [ i ] mem[i] ,以便之后使用。
当再次需要计算 d p [ i ] dp[i] d p [ i ] mem[i] 中获取结果,从而避免重复计算该子问题。
代码如下所示:
int dfs (int i, vector<int > &mem) if (i == 1 || i == 2 ) return i; if (mem[i] != -1 ) return mem[i]; int count = dfs (i - 1 , mem) + dfs (i - 2 , mem); mem[i] = count; return count; } int climbingStairsDFSMem (int n) vector<int > mem (n + 1 , -1 ) ; return dfs (n, mem); }
观察下图,经过记忆化处理后,所有重叠子问题都只需计算一次,时间复杂度优化至 O ( n ) O(n) O ( n ) ,这是一个巨大的飞跃。
记忆化搜索是一种“从顶至底”的方法 :我们从原问题(根节点)开始,递归地将较大子问题分解为较小子问题,直至解已知的最小子问题(叶节点)。之后,通过回溯逐层收集子问题的解,构建出原问题的解。
与之相反,动态规划是一种“从底至顶”的方法 :从最小子问题的解开始,迭代地构建更大子问题的解,直至得到原问题的解。
由于动态规划不包含回溯过程,因此只需使用循环迭代实现,无须使用递归。在以下代码中,我们初始化一个数组 dp 来存储子问题的解,它起到了与记忆化搜索中数组 mem 相同的记录作用:
int climbingStairsDP (int n) if (n == 1 || n == 2 ) return n; vector<int > dp (n + 1 ) ; dp[1 ] = 1 ; dp[2 ] = 2 ; for (int i = 3 ; i <= n; i++) { dp[i] = dp[i - 1 ] + dp[i - 2 ]; } return dp[n]; }
下图模拟了以上代码的执行过程。
与回溯算法一样,动态规划也使用“状态”概念来表示问题求解的特定阶段,每个状态都对应一个子问题以及相应的局部最优解。例如,爬楼梯问题的状态定义为当前所在楼梯阶数 i i i
根据以上内容,我们可以总结出动态规划的常用术语。
将数组 dp 称为 dp 表 ,d p [ i ] dp[i] d p [ i ] i i i
将最小子问题对应的状态(第 1 1 1 2 2 2 初始状态 。
将递推公式 d p [ i ] = d p [ i − 1 ] + d p [ i − 2 ] dp[i] = dp[i-1] + dp[i-2] d p [ i ] = d p [ i − 1 ] + d p [ i − 2 ] 状态转移方程 。
细心的读者可能发现了,由于 d p [ i ] dp[i] d p [ i ] d p [ i − 1 ] dp[i-1] d p [ i − 1 ] d p [ i − 2 ] dp[i-2] d p [ i − 2 ] dp 来存储所有子问题的解 ,而只需两个变量滚动前进即可。代码如下所示:
int climbingStairsDPComp (int n) if (n == 1 || n == 2 ) return n; int a = 1 , b = 2 ; for (int i = 3 ; i <= n; i++) { int tmp = b; b = a + b; a = tmp; } return b; }
观察以上代码,由于省去了数组 dp 占用的空间,因此空间复杂度从 O ( n ) O(n) O ( n ) O ( 1 ) O(1) O ( 1 )
在动态规划问题中,当前状态往往仅与前面有限个状态有关,这时我们可以只保留必要的状态,通过“降维”来节省内存空间。这种空间优化技巧被称为“滚动变量”或“滚动数组” 。
guangzhou_even
guangzhou_even的博客
本文是转载或翻译文章,版权归原作者所有。转载本文请联系原作者。